Maven中Package和Install的区别
Package是打包,打成Jar或War
Install表示将Jar或War安装到本地仓库中
什么是spring框架
Spring 是⼀种轻量级开发框架,旨在提⾼开发⼈员的开发效率以及系统的可维护性。Spring 官⽹:https://spring.io/。
我们⼀般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使⽤这些模块可以很⽅便地协助我们进⾏开发。
这些模块是:核⼼容器、数据访问/集成,、Web、AOP(⾯向切⾯编程)、⼯具、消息和测试模块。⽐如:Core Container 中的 Core 组件是Spring 所有组件的核⼼,Beans 组件和 Context 组件是实现IOC和依赖注⼊的基础,AOP组件⽤来实现⾯向切⾯编程。
Spring 官⽹列出的 Spring 的 6 个特征:
核⼼技术 :依赖注⼊(DI),AOP,事件(events),资源,i18n,验证,数据绑定,类型转换,SpEL。
- 测试 :模拟对象,TestContext框架,Spring MVC 测试,WebTestClient。
- 数据访问 :事务,DAO⽀持,JDBC,ORM,编组XML。
- Web⽀持 : Spring MVC和Spring WebFlux Web框架
- 集成 :远程处理,JMS,JCA,JMX,电⼦邮件,任务,调度,缓存。
- 语⾔ :Kotlin,Groovy,动态语⾔。
列举⼀些重要的Spring模块?
- Spring Core: 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IoC 依
赖注⼊功能。 - Spring Aspects : 该模块为与AspectJ的集成提供⽀持。
- Spring AOP :提供了⾯向切⾯的编程实现。
- Spring JDBC : Java数据库连接。
- Spring JMS :Java消息服务。
- Spring ORM : ⽤于⽀持Hibernate等ORM⼯具。
- Spring Web : 为创建Web应⽤程序提供⽀持。
- Spring Test : 提供了对 JUnit 和 TestNG 测试的⽀持。
@RestController vs @Controller
Controller 返回⼀个⻚⾯
单独使⽤ @Controller 不加 @ResponseBody 的话⼀般使⽤在要返回⼀个视图的情况,这种情况属于⽐传统的Spring MVC 的应⽤,对应于前后端不分离的情况
@RestController 返回JSON 或 XML 形式数据
但 @RestController 只返回对象,对象数据直接以 JSON 或 XML 形式写⼊ HTTP 响应(Response)中,这种情况属于 RESTful Web服务,这也是⽬前⽇常开发所接触的最常⽤的情况(前后端分离)
@Controller +@ResponseBody 返回JSON 或 XML 形式数据
如果你需要在Spring4之前开发 RESTful Web服务的话,你需要使⽤ @Controller 并结合 @ResponseBody 注解,也就是说 @Controller + @ResponseBody = @RestController (Spring 4)之后新加的注解
@ResponseBody 注解的作⽤是将 Controller 的⽅法返回的对象通过适当的转换器转换为指定的格式之后,写⼊到HTTP 响应(Response)对象的 body 中,通常⽤来返回 JSON 或者XML 数据,返回 JSON 数据的情况比较多。
常用注解
Spring依赖注入的方式
非注解方式注入:
- Set方法注入
- 构造器注入
- 静态工厂的方法注入
- 实例工厂的方法注入
注解方式注入:
1.@Autowired是自动注入,自动从spring的上下文找到合适的bean来注入 @Autowired(required=true)表示必须找到匹配的Bean,否则将报异常。
@Autowired默认按类型匹配注入Bean
在Spring中,@Autowired注入的类型可以是接口
比如,在Service层中注入Dao,如下示:
@Autowired
private UserDao userDao;
2.@Resource要求提供一个Bean名称的属性,如果属性为空,自动采用标注处的变量名和方法名作为Bean的名称 。
@Resource默认按名称匹配注入Bean
比如,在Controller层中注入Service,名称为Service的实现类,如下示
@Resource(name = "userServiceImpl")
private UserService userService;
另外要注意,@Resource是java自带的注解,不是Spring中的注解。@Resource注解完整的包路径为import javax.annotation.Resource;
3.@Qualifier 指定注入bean的名称
比如,在Controller层中注入Service,名称为Service的实现类,如下示
@Autowired
@Qualifier("userServiceImp")
private UserSerevice userService;
4.@Service,@Controller,@Repository分别标记类是Service层,Controller层,Dao层的类,spring扫描注解配置时,会标记这些类要生成bean。
@Repository用于标注数据访问组件,即DAO组件
@Service,@Controller 这些注解要放在接口的实现类上,而不是接口上面。
5.@Component是一种泛指,标记类是组件,spring扫描注解配置时,会标记这些类要生成bean。
6.@Scope用于指定Bean的作用范围
7.@Autowired和@Resource是用来修饰字段,构造函数,或者设置方法,并做注入的。
而@Service,@Controller,@Repository,@Component则是用来修饰类,标记这些类要生成bean。
Spring IOC & AOP
IOC参考:
AOP参考:https://www.cnblogs.com/joy99/p/10941543.html
谈谈⾃⼰对于 Spring IoC 和 AOP 的理解
IoC
IoC(Inverse of Control:控制反转)是⼀种设计思想,就是 将原本在程序中⼿动创建对象的控制权,交由Spring框架来管理。 IoC 在其他语⾔中也有应⽤,并⾮ Spring 特有。 IoC 容器是Spring ⽤来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。
AOP(Aspect-Oriented Programming:⾯向切⾯编程)
能够将那些与业务⽆关,却为业务模块所共同调⽤的逻辑或责任(例如事务处理、⽇志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
相关概念:
- 切面(aspect) : 类是对物体特征的抽象,切面就是对横切关注点的抽象
- 横切关注点: 对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点。
- 连接点(joinpoint) : 被拦截到的点,具体要拦截的东西,因为 Spring 只支持方法类型的连接点,所以在 Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器。
- 切入点(pointcut) : 对连接点进行拦截的定义
- 通知(advice) : 所谓通知指的就是指拦截到连接点之后要执行的代码, 通知分为前置、后置、异常、最终、环绕通知五类。
- 目标对象: 代理的目标对象
- 织入(weave) : 将切面应用到目标对象并导致代理对象创建的过程
- 引入(introduction) : 在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运⾏时增强,⽽ AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),⽽ AspectJ 基于字节码操作(Bytecode Manipulation)。
注:Spring中的AspectJ不是真正的使用了AspectJ,只是使用了AspectJ的指示器作为标识创建代理的方式而已,实际上实现AOP还是通过Cglib或JDK来实现的
两者区别:
| Spring AOP | AspectJ |
|---|---|
| 在纯 Java 中实现 | 使用 Java 编程语言的扩展实现 |
| 不需要单独的编译过程 | 除非设置 LTW,否则需要 AspectJ 编译器 (ajc) |
| 只能使用运行时织入 | 运行时织入不可用。支持编译时、编译后和加载时织入 |
| 功能不强-仅支持方法级编织 | 更强大 - 可以编织字段、方法、构造函数、静态初始值设定项、最终类/方法等......。 |
| 只能在由 Spring 容器管理的 bean 上实现 | 可以在所有域对象上实现 |
| 仅支持方法执行切入点 | 支持所有切入点 |
| 代理是由目标对象创建的, 并且切面应用在这些代理上 | 在执行应用程序之前 (在运行时) 前, 各方面直接在代码中进行织入 |
| 比 AspectJ 慢多了 | 更好的性能 |
| 易于学习和应用 | 相对于 Spring AOP 来说更复杂 |
Spring AOP 实现原理
AOP技术利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;
二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
AOP使用场景
日志记录、监控优化
2) 权限控制
3) 事务管理
4) 缓存
5) 持久化
Spring的IOC是单例模式的么?
IOC默认使用单例模式创建Bean,默认在spring容器启动时会自动创建对象。
但是也可以通过注解的方式实现多例模式,使用@Scope(value="prototype")
使用多例模式,在容器启动时不会创建bean,而在使用bean时才会去创建。
AOP代理可以是JDK动态代理或者CGLIB代理。
参考:https://blog.csdn.net/moreevan/article/details/11977115/
cglib和jdk动态代理区别有哪些
1、Jdk动态代理:利用拦截器(必须实现InvocationHandler)加上反射机制生成一个代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理
2、 Cglib动态代理:利用ASM框架,对代理对象类生成的class文件加载进来,通过修改其字节码生成子类来处理
什么时候用cglib什么时候用jdk动态代理?
1、目标对象生成了接口 默认用JDK动态代理
2、如果目标对象使用了接口,可以强制使用cglib
3、如果目标对象没有实现接口,必须采用cglib库,Spring会自动在JDK动态代理和cglib之间转换
JDK动态代理和cglib字节码生成的区别?
1、JDK动态代理只能对实现了接口的类生成代理,而不能针对类
2、Cglib是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法,并覆盖其中方法的增强,但是因为采用的是继承,所以该类或方法最好不要生成final,对于final类或方法,是无法继承的
Cglib比JDK快?
1、cglib底层是ASM字节码生成框架,但是字节码技术生成代理类,在JDL1.6之前比使用java反射的效率要高
2、在jdk6之后逐步对JDK动态代理进行了优化,在调用次数比较少时效率高于cglib代理效率
3、只有在大量调用的时候cglib的效率高,但是在1.8的时候JDK的效率已高于cglib
4、Cglib不能对声明final的方法进行代理,因为cglib是动态生成代理对象,final关键字修饰的类不可变只能被引用不能被修改
Spring bean
Spring 中的 bean 的作⽤域有哪些?
- singleton : 唯⼀ bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建⼀个新的 bean 实例。
- request : 每⼀次HTTP请求都会产⽣⼀个新的bean,该bean仅在当前HTTP request内有效。
- session : 每⼀次HTTP请求都会产⽣⼀个新的 bean,该bean仅在当前 HTTP session 内有效。
- global-session: 全局session作⽤域,仅仅在基于portlet的web应⽤中才有意义,Spring5已经没有了。Portlet是能够⽣成语义代码(例如:HTML)⽚段的⼩型Java Web插件。它们基于portlet容器,可以像servlet⼀样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
Spring 中的单例 bean 的线程安全问题了解吗?
⼤部分时候我们并没有在系统中使⽤多线程,所以很少有⼈会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同⼀个对象的时候,对这个对象的⾮静态成员变量的写操作会存在线程安全问题。
常⻅的有两种解决办法:
1. 在Bean对象中尽量避免定义可变的成员变量(不太现实)。
- 在类中定义⼀个ThreadLocal成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的⼀种⽅式)。
@Component 和 @Bean 的区别是什么?
- 作⽤对象不同: @Component 注解作⽤于类,⽽ @Bean 注解作⽤于⽅法。
- @Component 通常是通过类路径扫描来⾃动侦测以及⾃动装配到Spring容器中(我们可以使⽤ @ComponentScan 注解定义要扫描的路径从中找出标识了需要装配的类⾃动装配到Spring 的 bean 容器中)。 @Bean 注解通常是我们在标有该注解的⽅法中定义产⽣这个bean, @Bean 告诉了Spring这是某个类的示例,当我需要⽤它的时候还给我。
- @Bean 注解⽐ Component 注解的⾃定义性更强,⽽且很多地⽅我们只能通过 @Bean 注解来注册bean。⽐如当我们引⽤第三⽅库中的类需要装配到 Spring 容器时,则只能通过@Bean 来实现。
将⼀个类声明为Spring的 bean 的注解有哪些?
我们⼀般使⽤ @Autowired 注解⾃动装配 bean,要想把类标识成可⽤于 @Autowired 注解⾃动装配的 bean 的类,采⽤以下注解可实现:
- @Component :通⽤的注解,可标注任意类为 Spring 组件。如果⼀个Bean不知道属于哪个层,可以使⽤ @Component 注解标注。
- @Repository : 对应持久层即 Dao 层,主要⽤于数据库相关操作。
- @Service : 对应服务层,主要涉及⼀些复杂的逻辑,需要⽤到 Dao层。
- @Controller : 对应 Spring MVC 控制层,主要⽤户接受⽤户请求并调⽤ Service 层返回数据给前端⻚⾯。
Spring 中的 bean ⽣命周期


-
Bean 容器找到配置⽂件中 Spring Bean 的定义。
-
Bean 容器利⽤ Java Reflection API 创建⼀个Bean的实例。
-
如果涉及到⼀些属性值 利⽤ set() ⽅法设置⼀些属性值
-
如果 Bean 实现了 BeanNameAware 接⼝,调⽤ setBeanName() ⽅法,传⼊Bean的名字。
-
如果 Bean 实现了 BeanClassLoaderAware 接⼝,调⽤ setBeanClassLoader() ⽅法,传
ClassLoader 对象的实例。 -
与上⾯的类似,如果实现了其他 *.Aware 接⼝,就调⽤相应的⽅法。
-
如果有和加载这个 Bean 的 Spring 容器相关的 BeanPostProcessor 对象,执
⾏ postProcessBeforeInitialization() ⽅法 -
如果Bean实现了 InitializingBean 接⼝,执⾏ afterPropertiesSet() ⽅法。
-
如果 Bean 在配置⽂件中的定义包含 init-method 属性,执⾏指定的⽅法
-
如果有和加载这个 Bean的 Spring 容器相关的 BeanPostProcessor 对象,执
⾏ postProcessAfterInitialization() ⽅法 -
当要销毁 Bean 的时候,如果 Bean 实现了 DisposableBean 接⼝,执⾏ destroy() ⽅法。
-
当要销毁 Bean 的时候,如果 Bean 在配置⽂件中的定义包含 destroy-method 属性,执⾏指
定的⽅法。
Spring Bean的生命周期分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean。整理如下:
四个阶段
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
多个扩展点
- 影响多个Bean
- BeanPostProcessor
- InstantiationAwareBeanPostProcessor
- 影响单个Bean
- Aware
- Aware Group1
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
- Aware Group2
- EnvironmentAware
- EmbeddedValueResolverAware
- ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware)
- Aware Group1
- 生命周期
- InitializingBean
- DisposableBean
- Aware
主要过程
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
实例化 -> 属性赋值 -> 初始化 -> 销毁
主要逻辑都在doCreate()方法中,逻辑很清晰,就是顺序调用以下三个方法,这三个方法与三个生命周期阶段一一对应
- createBeanInstance() -> 实例化
- populateBean() -> 属性赋值
- initializeBean() -> 初始化
InstantiationAwareBeanPostProcessor作用于实例化阶段的前后,BeanPostProcessor作用于初始化阶段的前后。正好和第一、第三个生命周期阶段对应。通过图能更好理解:

InstantiationAwareBeanPostProcessor实际上继 承了BeanPostProcessor接口
InstantiationAwareBeanPostProcessor方法分析
在InstantiationAwareBeanPostProcessor当中 postProcessBeforeInstantiation方法 在doCreateBean之前调用,也就是在bean实例化之前调用的,英文源码注释解释道该方法的返回值会替换原本的Bean作为代理,这也是Aop等功能实现的关键点。
之后执行populateBean 也就是赋值阶段 continueWithPropertyPopulation 初始的boolean值为true
postProcessAfterInstantiation方法在属性赋值方法内,但是在真正执行赋值操作之前。其返回值为boolean,返回false时可以阻断属性赋值阶段 也就是说当实例化阶段之后还没完成的情况下是不能继续执行属性赋值
注意点:
spring aop替换对象的时候并不在postProcessBeforeInstantiation替换对象,而是在 postProcessAfterInitialization处理的
一般情况下是在postProcessAfterInitialization替换代理类,自定义了TargetSource的情况下在postProcessBeforeInstantiation替换代理类。具体逻辑在AbstractAutoProxyCreator类中。
Aware接口
Aware类型的接口的作用就是让我们能够拿到Spring容器中的一些资源。基本都能够见名知意,Aware之前的名字就是可以拿到什么资源,例如BeanNameAware可以拿到BeanName,以此类推。调用时机需要注意:所有的Aware方法都是在初始化阶段之前调用的!
在initializeBean方法中有一个invokeAwareMethods方法 这个方法是在初始化bean的阶段之前完成的
但是不是所有的Aware接口都使用同样的方式调用。Bean××Aware都是在代码中直接调用的,而ApplicationContext相关的Aware都是通过BeanPostProcessor#postProcessBeforeInitialization()实现的。
之后BeanPostProcessor的调用机制就开始体现出来了 通过invokeInitMethod方法的实现在 applyBeanPostProcessorsBeforeInitialization 和 applyBeanPostProcessorsAfterInitialization 之间进行完成
参考连接:
https://www.jianshu.com/p/1dec08d290c1
ApplicationContext和BeanFactory的区别
BeanFactory:
是Spring里面最低层的接口,提供了最简单的容器的功能,只提供了实例化对象和拿对象的功能;
ApplicationContext:
应用上下文,继承BeanFactory接口,它是Spring的一各更高级的容器,提供了更多的有用的功能;
-
国际化(MessageSource)
-
访问资源,如URL和文件(ResourceLoader)
-
载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
-
消息发送、响应机制(ApplicationEventPublisher)
-
AOP(拦截器)
两者装载bean的区别
BeanFactory:
BeanFactory在启动的时候不会去实例化Bean,中有从容器中拿Bean的时候才会去实例化;
ApplicationContext:
ApplicationContext在启动的时候就把所有的Bean全部实例化了。它还可以为Bean配置lazy-init=true来让Bean延迟实例化;
我们该用BeanFactory还是ApplicationContent
延迟实例化的优点:(BeanFactory)
应用启动的时候占用资源很少;对资源要求较高的应用,比较有优势;
不延迟实例化的优点: (ApplicationContext)
- 所有的Bean在启动的时候都加载,系统运行的速度快;
- 在启动的时候所有的Bean都加载了,我们就能在系统启动的时候,尽早的发现系统中的配置问题
- 建议web应用,在启动的时候就把所有的Bean都加载了。(把费时的操作放到系统启动中完成)
https://blog.csdn.net/pythias_/article/details/82752881
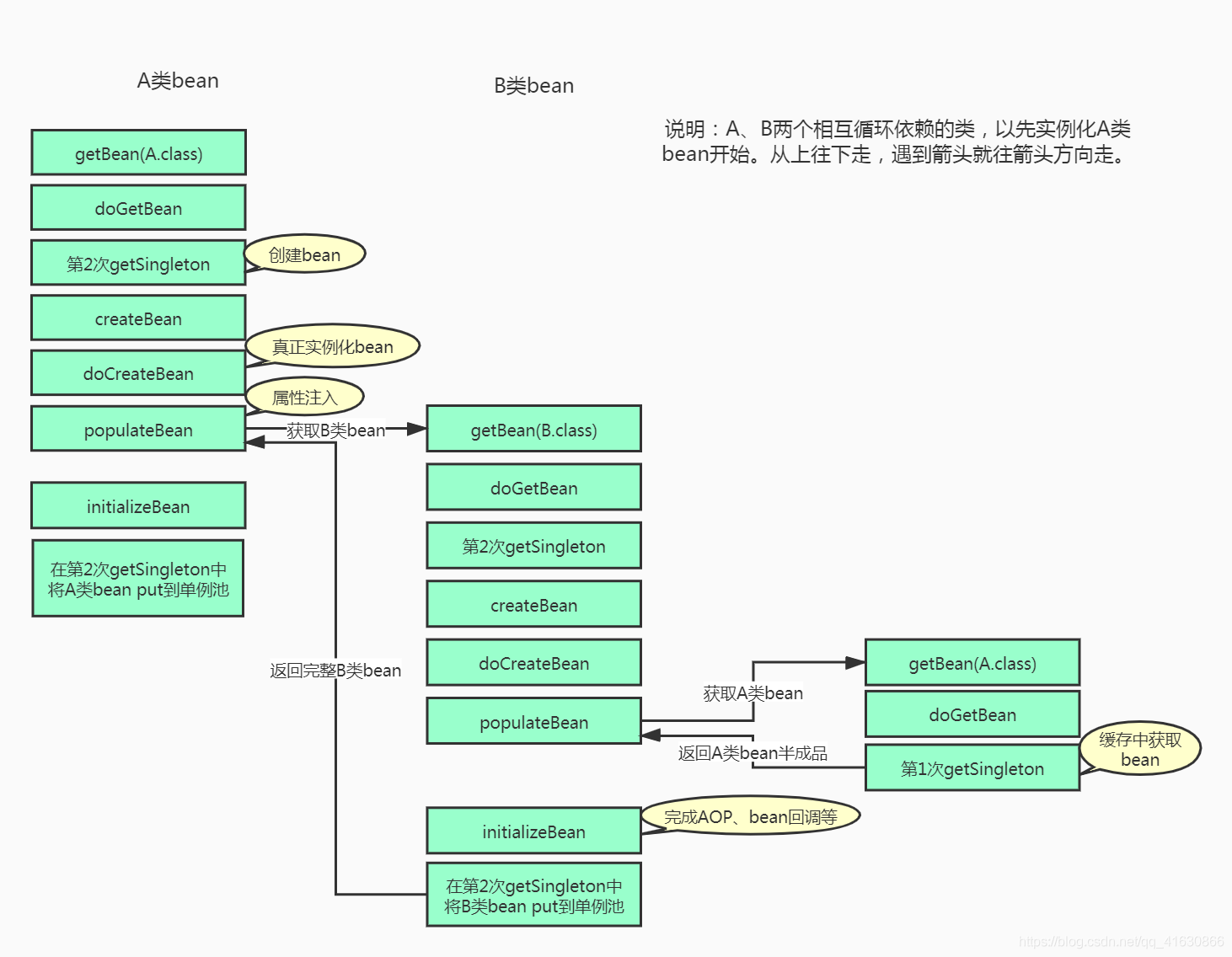
spring如何解决循环依赖问题
简言之,两个池子:一个成品池子,一个半成品池子。能解决循环依赖的前提是:spring开启了allowCircularReferences,那么一个正在被创建的bean才会被放在半成品池子里。在注入bean,向容器获取bean的时候,优先向成品池子要,要不到,再去向半成品池子要。
出现循环依赖一定是你的业务设计有问题。高层业务和底层业务的划分不够清晰,一般,业务的依赖方向一定是无环的,有环的业务,在后续的维护和拓展一定非常鸡肋
参考连接:
-
https://blog.csdn.net/qq_41630866/article/details/104332517
https://blog.csdn.net/chaitoudaren/article/details/105060882
https://blog.csdn.net/likun557/article/details/113977261
https://cloud.tencent.com/developer/article/1497692
-
Spring使用了三级缓存 + 提前暴露对象的方式来解决循环依赖的问题。
-
Spring解决循环依赖的条件:
- 出现循环依赖的Bean必须是单例的。
- 依赖注入的方式不能全是构造器注入的方式。
-
相关的重要属性:位于
DefaultSingletonBeanRegistry类中-
Spring内部维护了三个Map,所谓的三重缓存。
-
Map<String, Object> singletonObjects:单例池容器,用于缓存单例Bean的地方。一级缓存。
- 这里的bean是已经创建完成的,该bean经历过实例化->属性填充->初始化以及各类的后置处理。因此,一旦需要获取bean时,我们第一时间就会寻找一级缓存
-
Map<String, Object> earlySingletonObjects:早期的单例Bean。二级缓存。
- 这里跟一级缓存的区别在于,该缓存所获取到的bean是提前曝光出来的,是还没创建完成的。也就是说获取到的bean只能确保已经进行了实例化,但是属性填充跟初始化肯定还没有做完,因此该bean还没创建完成,仅仅能作为指针提前曝光,被其他bean所引用
-
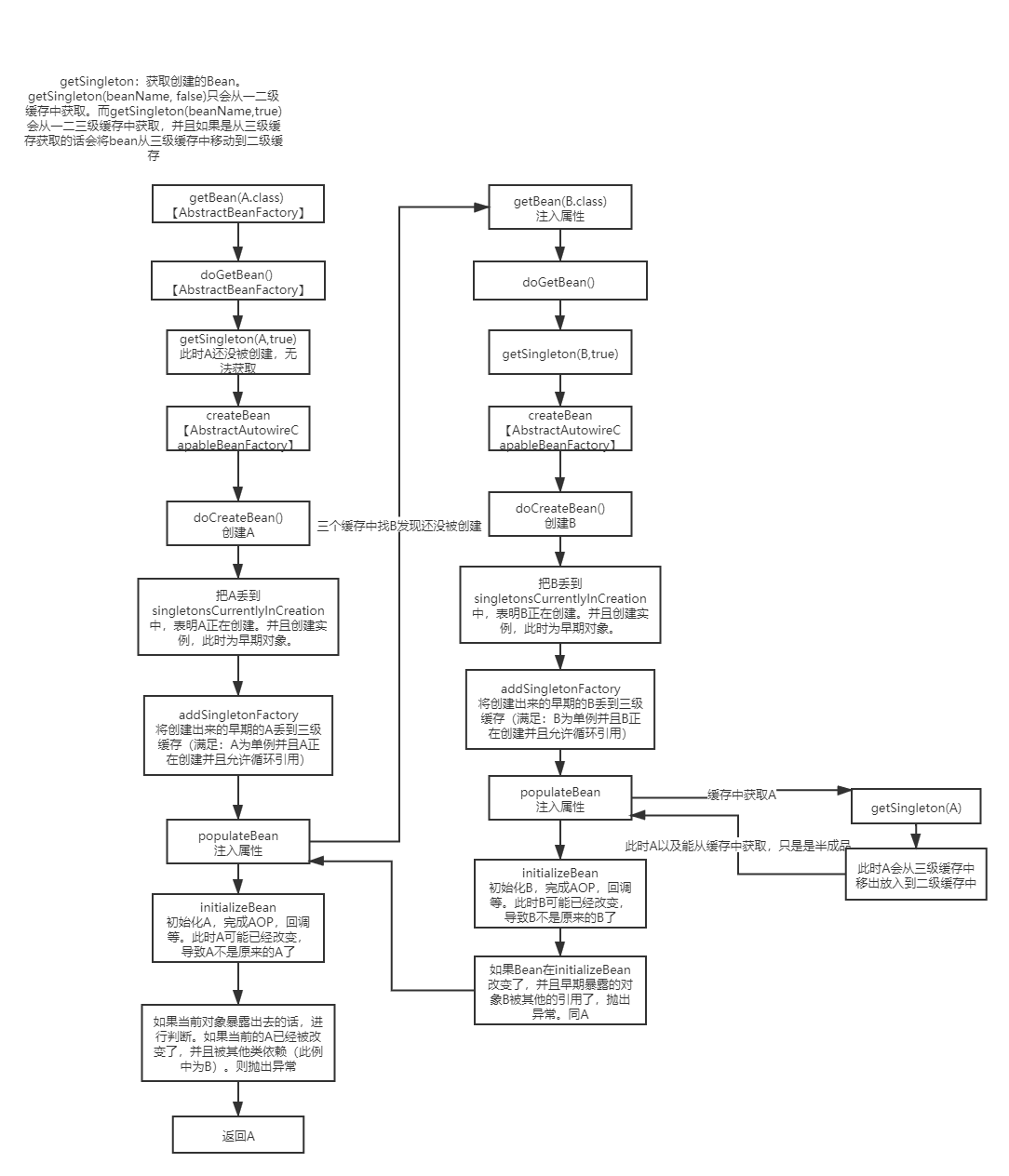
Map<String, ObjectFactory<?>> singletonFactories:创建中单例Bean的原始工厂。三级缓存。
- 在bean实例化完之后,属性填充以及初始化之前,如果允许提前曝光,spring会将实例化后的bean提前曝光,也就是把该bean转换成beanFactory并加入到三级缓存。在需要引用提前曝光对象时再通过singletonFactory.getObject()获取。
- 当其他的bean从三级缓存中获取了Bean后,当前的Bean就会从三级缓存中放入到二级缓存。并且从三级缓存中取出的时候会调用
SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference方法。
-
-
Set<String> singletonsCurrentlyInCreation:保存了当前正在创建的单例对象的名称。 -
Map<String, Set<String>> dependentBeanMap:保存了一个bean对其他的bean的依赖。
-
-
注意:
- 第一级缓存(singletonObjects)是用来缓存创建好的单例Bean的
- 第二级缓存(earlySingletonObjects)是用来发现在当前Bean被暴露的时间里,有没有被其他Bean引用,如果被其他Bean引用,其他Bean又是引用的一个错误版本,就抛出一个异常。
- 第三级缓存(singletonFactories),这个才是SP真正用来解决循环依赖的,并且可以延迟代理的时机。
// AbstractAutowireCapableBeanFactory#doCreateBean /*忽略部分代码*/ // 创建实例包装 if (instanceWrapper == null) { instanceWrapper = createBeanInstance(beanName, mbd, args); } // 从实例包装后获取Bean Object bean = instanceWrapper.getWrappedInstance(); /*忽略部分代码*/ if (earlySingletonExposure) { /*忽略部分代码*/ // 如果允许暴露,则将其加入二级缓存。在调用被取出来的时候会调用SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference方法,默认实现只有AbstractAutoProxyCreator,创建代理。因此,如果在被暴露的过程中,有其他Bean调用getSingleton(当前对象),则当前对象会被代理(如果有的话),然后放入二级缓存。 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); } /*忽略部分代码*/ Object exposedObject = bean; try { // 填充属性 populateBean(beanName, mbd, instanceWrapper); // 实例化Bean,请注意这里,实例化Bean的时候可能会导致exposedObject的改变!!! exposedObject = initializeBean(beanName, exposedObject, mbd); } catch (Throwable ex) { /*忽略部分代码*/ } if (earlySingletonExposure) { // 直接从二级缓存或一级缓存中获取Bean,注意,这里如果不为null,只有一种可能,在暴露出去的时间里,在其他Bean的初始化过程中调用了getSingleton(当前Bean)。 Object earlySingletonReference = getSingleton(beanName, false); if (earlySingletonReference != null) { // 判断exposedObject在经过initializeBean后是否和原来的Bean是一个对象。 if (exposedObject == bean) { // 如果bean没有在initializeBean改变,那么将当前Bean替换为代理后(如果有代理过的话)的Bean。 exposedObject = earlySingletonReference; } else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) { /*忽略部分代码*/ // 注意:到了这里,说明了一种情况,当前暴露出去的Bean(可能被代理过后)被其他Bean引用了,但是在实例化Bean的时候,Bean和暴露出去的Bean已经不是一个Bean的,即其他Bean引用的Bean是一个错误的Bean。因此如果有其他的Bean实际引用了当前Bean,则应该抛出一个异常。为什么是实际引用呢?因为这里可能其他Bean只是实现了Aware之类的接口,并在里面调用了getSingleton(当前Bean),并没有实际引用。 } } }Copy to clipboardErrorCopied -
问题:
-
如何解决循环依赖的:
- 通过提前曝光解决循环依赖,当AB循环依赖的时候,先将A的半成品曝光出去,让B先完成初始化,然后在使得初始化完成后的B注入到A中。
-
为什么要三级缓存:(以下为自己理解,不一定准确,事实上,添加三级缓存的地方的注释也标注了三级缓存是用来解决潜在的循环依赖的。)
-
很多博文说三级缓存是为了解决AOP的循环依赖,但事实上不是这样的,即使没有三级缓存,Spring也可以通过提前暴露代理对象的方法来解决AOP的循环依赖。
-
所以三级缓存的作用主要是:延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象。
-
对于代理过的对象,如果在被暴露出去的时候被其他的Bean所引用了,就会在从三级缓存中移除的时候创建代理;如果没有被引用的话,则在初始化Bean的时候创建代理。
-
三级缓存作用:(三级缓存并非非要不可)
- 通过
SmartInstantiationAwareBeanPostProcessor对Bean进行扩展。 - 尽量可能的延迟AOP的初始化。
- 通过
-

// AbstractAutowireCapableBeanFactory#doCreateBean // 忽略部分代码 if (earlySingletonExposure) { if (logger.isTraceEnabled()) { logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references"); } // 添加三级缓存 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); } // 忽略部分代码 // AbstractAutowireCapableBeanFactory#getEarlyBeanReference protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) { // 这里实现了getEarlyBeanReference的只有一个AbstractAutoProxyCreator.java exposedObject = bp.getEarlyBeanReference(exposedObject, beanName); } } return exposedObject; }
-
-
-
Spring MVC
说说⾃⼰对于 Spring MVC 了解?
谈到这个问题,我们不得不提提之前 Model1 和 Model2 这两个没有 Spring MVC 的时代。
- Model1 时代 : 很多学 Java 后端⽐晚的朋友可能并没有接触过 Model1 模式下的JavaWeb 应⽤开发。在 Model1 模式下,整个 Web 应⽤⼏乎全部⽤ JSP ⻚⾯组成,只⽤少量的 JavaBean 来处理数据库连接、访问等操作。这个模式下 JSP 即是控制层⼜是表现层。显⽽易⻅,这种模式存在很多问题。⽐如①将控制逻辑和表现逻辑混杂在⼀起,导致代码重⽤率极低;②前端和后端相互依赖,难以进⾏测试并且开发效率极低;
- Model2 时代 :学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+JSP(View,)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。Model:系统涉及的数据,也就是 dao 和 bean。View:展示模型中的数据,只是⽤来展。Controller:处理⽤户请求都发送给 ,返回数据给 JSP 并展示给⽤户。
Model2 模式下还存在很多问题,Model2的抽象和封装程度还远远不够,使⽤Model2进⾏开发时不可避免地会重复造轮⼦,这就⼤⼤降低了程序的可维护性和复⽤性。于是很多JavaWeb开发相关的 MVC 框架应运⽽⽣⽐如Struts2,但是 Struts2 ⽐笨重。随着 Spring 轻量级开发框架的流⾏,Spring ⽣态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相⽐于Struts2 , Spring MVC 使⽤更加简单和⽅便,开发效率更⾼,并且 Spring MVC 运⾏速度更快。MVC 是⼀种设计模式,Spring MVC 是⼀款很优秀的 MVC 框架。Spring MVC 可以帮助我们进⾏更简洁的Web层的开发,并且它天⽣与 Spring 框架集成。Spring MVC 下我们⼀般把后端项⽬分为 Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台⻚⾯)。
SpringMVC ⼯作原理了解吗?

流程:
- 客户端(浏览器)发送请求,直接请求到 DispatcherServlet 。
- DispatcherServlet 根据请求信息调⽤ HandlerMapping ,解析请求对应的 Handler 。
- 解析到对应的 Handler (也就是我们平常说的 Controller 控制器)后,开始HandlerAdapter 适配器处理。
- HandlerAdapter 会根据 Handler 来调⽤真正的处理器开处理请求,并处理相应的业务逻辑。
- 处理器处理完业务后,会返回⼀个 ModelAndView 对象, Model 是返回的数据对象, View 是个逻辑上的 View 。
- ViewResolver 会根据逻辑 View 查找实际的 View 。
- DispaterServlet 把返回的 Model 传给 View (视图渲染)。
- 把 View 返回给请求者(浏览器)
Spring SpringMVC和SpringBoot区别
一、概念
1、Spring
Spring是一个开源容器框架,可以接管web层,业务层,dao层,持久层的组件,并且可以配置各种bean,和维护bean与bean之间的关系。其核心就是控制反转(IOC),和面向切面(AOP),简单的说就是一个分层的轻量级开源框架。
2、SpringMVC
Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。SpringMVC是一种web层mvc框架,用于替代servlet(处理|响应请求,获取表单参数,表单校验等。SpringMVC是一个MVC的开源框架,SpringMVC=struts2+spring,springMVC就相当于是Struts2加上Spring的整合。
3、SpringBoot
Springboot是一个微服务框架,延续了spring框架的核心思想IOC和AOP,简化了应用的开发和部署。Spring Boot是为了简化Spring应用的创建、运行、调试、部署等而出现的,使用它可以做到专注于Spring应用的开发,而无需过多关注XML的配置。提供了一堆依赖打包,并已经按照使用习惯解决了依赖问题—>习惯大于约定。
二区别与总结
1.简单理解为:Spring包含了SpringMVC,而SpringBoot又包含了Spring或者说是在Spring的基础上做得一个扩展。

2、关系大概就是这样:
spring mvc < spring < springboot
Spring 框架中⽤到了哪些设计模式
1.工厂设计模式:Spring使用工厂模式通过BeanFactory和ApplicationContext创建bean对象。
2.代理设计模式:Spring AOP功能的实现。
3.单例设计模式:Spring中的bean默认都是单例的。
4.模板方法模式:Spring中的jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。
5.包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
6.观察者模式:Spring事件驱动模型就是观察者模式很经典的一个应用。
7.适配器模式:Spring AOP的增强或通知(Advice)使用到了适配器模式、Spring MVC中也是用到了适配器模式适配Controller。
https://blog.csdn.net/fei1234456/article/details/106693892
Spring 事务
Spring 管理事务的⽅式有⼏种?
- 编程式事务,在代码中硬编码。(不推荐使⽤)
- 声明式事务,在配置⽂件中配置(推荐使⽤)
声明式事务⼜分为两种:
- 基于XML的声明式事务
- 基于注解的声明式事务 Transactional
Spring 事务中的隔离级别有哪⼏种?
- TransactionDefinition.I SOLATION_DEFAULT: 使⽤后端数据库默认的隔离级别,Mysql默认采⽤的 REPEATABLE_READ隔离级别 Oracle 默认采⽤的 READ_COMMITTED隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻⽌脏读,但是幻读或不可重复读仍有可能发⽣
- TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同⼀字段的多次读取结果都是⼀致的,除⾮数据是被本身事务⾃⼰所修改,可以阻⽌脏读和不可重复读,但幻读仍有可能发⽣。
- TransactionDefinition.ISOLATION_SERIALIZABLE: 最⾼的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执⾏,这样事务之间就完全不可能产⽣⼲扰,也就是说,该级别可以防⽌脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会⽤到该级别。
Spring 事务中哪⼏种事务传播⾏为?
⽀持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加⼊该事务;如果当前没有事务,则创建⼀个新的事务。
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加⼊该事务;如果当前没有事务,则以⾮事务的⽅式继续运⾏。
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加⼊该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不⽀持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建⼀个新的事务,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以⾮事务⽅式运⾏,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NEVER: 以⾮事务⽅式运⾏,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建⼀个事务作为当前事务的嵌套事务来运⾏;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
@Transactional(rollbackFor = Exception.class)注解了解吗?
我们知道:Exception分为运⾏时异常RuntimeException和⾮运⾏时异常。事务管理对于企业应⽤来说是⾄关重要的,即使出现异常情况,它也可以保证数据的⼀致性。
当 @Transactional 注解作⽤于类上时,该类的所有 public ⽅法将都具有该类型的事务属性,同时,我们也可以在⽅法级别使⽤该标注来覆盖类级别的定义。如果类或者⽅法加了这个注解,那么这个类⾥⾯的⽅法抛出异常,就会回滚,数据库⾥⾯的数据也会回滚。
在 @Transactional 注解中如果不配置 rollbackFor 属性,那么事物只会在遇到 RuntimeException 的时候才会回滚,加上 rollbackFor=Exception.class ,可以让事物在遇到⾮运⾏时异常时也
springboot和spring MVC的区别是什么
Spring 最初利用“工厂模式”(DI)和“代理模式”(AOP)解耦应用组件。大家觉得挺好用,于是按照这种模式搞了一个 MVC框架(一些用Spring 解耦的组件),用开发 web 应用( SpringMVC )。然后发现每次开发都写很多样板代码,为了简化工作流程,于是开发出了一些“懒人整合包”(starter),这套就是 Spring Boot。
所以,用最简练的语言概括就是:
Spring 是一个“引擎”;
Spring MVC 是基于Spring的一个 MVC 框架;
Spring Boot 是基于Spring4的条件注册的一套快速开发整合
JPA
如何使⽤JPA在数据库中⾮持久化⼀个字段?
假如我们有有下⾯⼀个类:

如果我们想让 secrect 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采⽤下⾯⼏种⽅法:

spring线程安全问题
spring 的 bean 的scope
spring容器中管理的bean有五种作用域:
1、singleton:单例、也是默认的
2、prototype:原型,即每次需要该bean都会创建一个新的bean
3、request:请求级别,即每次请求创建一个bean,适用于WebApplicationContext
4、session:session会话级别,同一个session共享一个bean
5、application:应用程序级别,同一个程序共享一个bean
从单例与原型Bean,去说线程安全
对于原型模式的Bean,每次都会创建一个新对象,也就是线程之间并不存在Bean共享,不会有线程安全的问题。
对于单例Bean,所有线程都共享一个单例实例Bean,因此是存在资源的竞争。
如果单例Bean,是一个无状态Bean,也就是线程中的操作不会对Bean的成员执行查询以外的操作,那么这个单例Bean是线程安全的。
比如spring mvc 的 Controller、Service、Dao等,这些Bean大多是无状态的,只关注于方法本身。
对于有状态的bean,spring官方提供的bean,一般提供了通过ThreadLocal去解决线程安全的方法。
比如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等。
使用ThreadLocal的好处是使得多线程场景下,多个线程对这个单例Bean的成员变量并不存在资源的竞争,因为ThreadLocal为每个线程保存线程私有的数据。这是一种以空间换时间的方式。
spring中 单例模式和原型模式的区别
简单说来,单例就是用的一个对象。 原型就是拷贝的这个对象。
单例模式和原型模式多次调用hashcode相同么
单例模式多次调用hashcode是相同的。
原型模式多次调用hashcode是不同的。
如何在spring中验证原型模式hashcode不同
在2个类中,分别注入一个原型模式的对象,打印hashcode就可以看出来。
注: 一个类中是看不出来的,因为一个类中注入的时候只调用一次。
有个需求,当每次调用这个对象的时候,生成一个新日期,用bean的形式好么
这个要区分下情况。
如果this.date=new Date(); 写在构造器里是不好用的,因为bean只加载一次。 这个new Date()只在spring创建对象的时候执行一次。 所以一直不变。
解决方案:
可以把this.date=new Date(); 写在一个方法里,然后再返回该bean对象,方法每次调用都会执行一遍逻辑,所以date会变化。
原型模式
存在一个对象,每次新建对象都是拷贝这个对象的属性值
分为浅复制与深复制
区别在于对象里面的引用类型对象属性是否是同一个
JWT原理
参考https://blog.csdn.net/lh_hebine/article/details/99695927
JWT是为了在网络应用环境之间传递声明而执行的一种基于JSON 的开放标准
JWT组成
头部
声明类型
加密算法
再进行base加密得到第一部分
载荷 用于存放有效的信息 不存放敏感的信息
标准中注册的声明
公共的声明
私有的声明
再进行base加密得到第二部分
签证
header base加密后
payload base加密后
secret
通过前两者的加密后字符串 再通过头部声明的加密算法进行加密组成第三部分
JWT认证流程
在前后端分离的项目中:前端将用户的登录信息发送给服务器;服务器接受请求后为用户生成独一无二的认证信息--token,传给客户端浏览器;客户端将token保存在cookie或者storage中;在之后访问客户端都携带这个token请求服务器;服务器验证token的值,如果验证成功则给客户端返回数据。服务器并不保存token。
maven是怎样解决依赖冲突的
用Maven Helper插件,在插件安装好之后,我们打开pom.xml文件,在底部会多出一个Dependency Analyzer选项
点击 Dependency Analyzer,通过点击conflicts发现冲突,通过如下的方式在解决冲突;
maven自动解决依赖冲突的规则是什么?
第一原则:路径最近者优先
项目A有如下的依赖关系:
A->B->C->X(1.0)
A->D->X(2.0)
则该例子中,X的版本是2.0
第二原则:路径相等,先声明者优先
项目A有如下的依赖关系:
A->B->Y(1.0)
A->C->Y(2.0)
若pom文件中B的依赖坐标先于C进行声明,则最终Y的版本为1.0